Microsoft has opened sourced another interesting model.
Phi-4-reasoning vision 15B is a multimodal inference model with a parameter scale of 15B, focusing on lightweight design. The key numbers are not parameters, but the amount of tokens used for training -200B. It's not trillions, it's 200B. This magnitude is quite restrained in today's big model race.
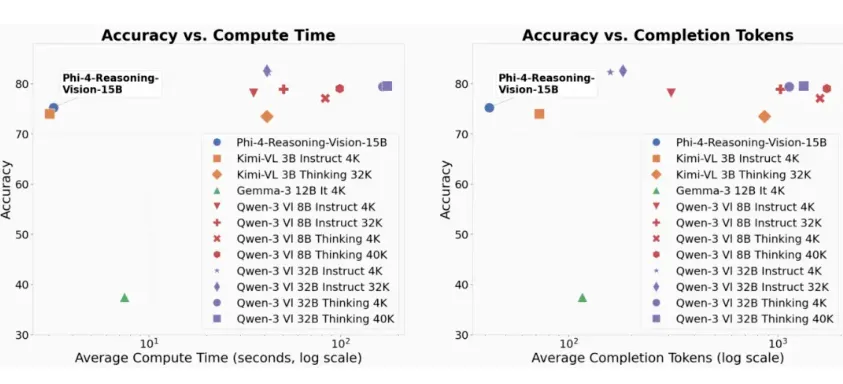
How did the 'little steel cannon' do it
The training data volume of large models in the industry is usually in the trillion level, and it has almost become a consensus that the more tokens, the stronger the ability. The idea of Phi-4-reasoning vision is reversed: data quality takes priority over data quantity.
The R&D team has done several things at the data level: deep cleaning of open source data to remove low-quality noise; Generate directional synthesis data to make the model targeted for specific tasks; One interesting finding of precise domain data matching is that increasing the proportion of mathematical data can simultaneously enhance computer operational capabilities. These two abilities may seem unrelated, but there is an inherent connection behind them.
The effectiveness of this strategy has been validated in benchmark tests. Phi-4-reasoning vision performs outstandingly in scientific reasoning and screen localization tasks. For a 15B scale model, this achievement exceeds expectations.
Hybrid reasoning path: separate processing of simple and complex tasks
The most practical design of this model is a hybrid inference path.
When faced with simple tasks such as image description and OCR, the model defaults to direct response mode, which is fast and does not take any detours. When encountering complex logical tasks such as mathematical formulas and scientific charts, the model will automatically call structured thought chain paths to ensure the accuracy of the answers. Users can also manually switch between two modes through specific guiding words.
The essence of this design is to allocate computing power according to demand. Not all problems require deep thinking, but large models often treat each problem as a complex one, resulting in wastage of efficiency. Phi-4-reasoning vision solves this problem at the architecture level - the model itself determines how deep thinking is needed for this task.
The perception capability brought by SigLIP-2 encoder
Another key component is the SigLIP-2 dynamic resolution encoder. This encoder enables the model to have strong perceptual ability for small elements in high-resolution screenshots - UI elements such as buttons, input boxes, and drop-down menus can be accurately recognized and located.
This ability directly points to an application scenario: Computer Operations Assistant (CUA). That is to say, Phi-4-reasoning vision can serve as a part of an AI programming assistant, helping users automatically operate web or mobile interfaces - clicking on buttons when they see them, filling in input boxes when they see them, and doing so under the fine perception of high-resolution screenshots.
This is a step forward from simple OCR: not just understanding what is written on the screen, but knowing what each element on the screen is and what it is used for.
What is the value of lightweight models
The open source of Phi-4-reasoning vision corresponds to a clear market demand: not everyone needs to run large models with billions of parameters, and many practical tasks do not require such strong capabilities, but need to run efficiently in local or resource constrained environments.
The 15B scale means it can run on consumer grade GPUs, while the 200B token training ensures that inference efficiency is not too low. For developers, this is an option to run and do practical projects on their own machines, rather than just calling cloud APIs.
Microsoft's positioning for this product is "a compact model that proves smaller, faster, and stronger". From a technical perspective, this proof is valid. But the limitations of lightweight models should also be recognized - there is still a gap between them and large models in complex tasks that require extremely strong reasoning abilities.
Lightweight and large models are not substitutes, but rather a division of labor in different scenarios. The value of Phi-4-reasoning vision lies in lowering the threshold for multimodal reasoning ability.
