Event core: Microsoft's open source "killer move"
On April 7th, the Microsoft Bing team dropped a small bomb - the officially open source word embedding model series called "Harrier".
I say 'neither big nor small' because embedded models don't sound as sexy, unlike big language models that can write poetry, draw, or chat with you. But calling it a bomb is because this field is too critical - it is the "foundation" of search, retrieval, and RAG systems, determining whether AI can accurately find and understand information.
The most eye-catching thing is that the flagship 27B model surpassed mainstream proprietary models such as OpenAI, Amazon, and Google Gemini in the multilingual MTEB v2 benchmark test, ranking first. Microsoft is not open sourcing a 'pretty good' model, but rather an 'currently best' model.
This is not doing charity, this is playing a bigger game of chess.
Technical Insight: Why Harrier Can Win?
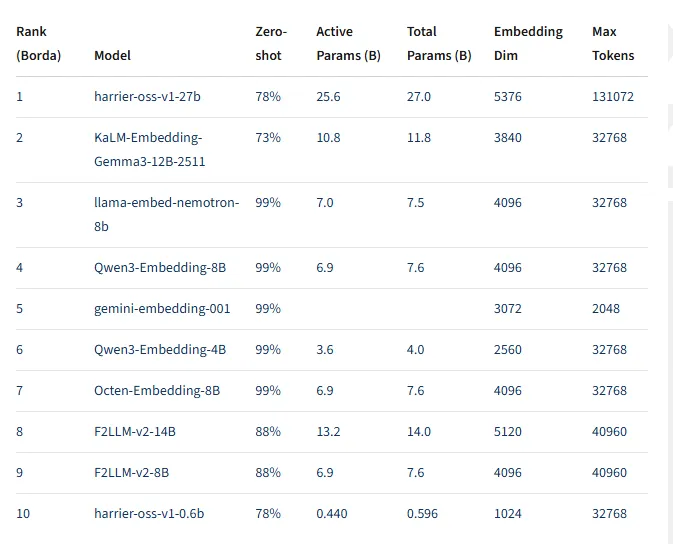
First, let's take a look at the hard indicators: support for over 100 languages, with a contextual window of up to 32000 words. This number belongs to the top-level configuration in the field of embedded models. Most embedded models still have context windows in the range of 512-2048, and Harrier directly pulls it up to 32K, which means it can handle complete long documents instead of cutting articles into pieces and barely piecing them together.
What's even more worth pondering is the training strategy. Microsoft has used over 2 billion real-life examples, which is already an astonishing number. But what's really interesting is that they also introduced synthetic data from GPT-5 for reinforcement.
wait, GPT-5? Has OpenAI's GPT-5 not been released yet?
There are two possibilities here: either the collaboration between Microsoft and OpenAI is deeper than the outside world imagines, and Microsoft has obtained the training data or synthesis capability of GPT-5 in advance; Either 'from GPT-5' is a marketing term referring to some kind of GPT-4 enhanced version or undisclosed intermediate version. In either case, it indicates that Microsoft has invested heavily in data quality.
The combination of high-quality real data and high-quality synthetic data gives Harrier a significant advantage in understanding complex contexts and processing long texts. This is not a simple 'miracle with great force', but a precise strike of 'good data+good methods'.
Industry Panorama Analysis: The "Arms Race" of Embedded Models
Embedding models is an easily overlooked but crucial track. It doesn't stand in the spotlight like a big language model, but it is the "eye" of the entire AI system - responsible for converting text into vectors, allowing machines to understand semantics, calculate similarity, and retrieve relevant information.
In the RAG (Retrieval Enhanced Generative) system, the performance of the embedded model directly determines the accuracy of retrieval. You ask a question, the system needs to first find relevant documents from the knowledge base before the large model can generate answers. If the embedded model is not good enough, the documents found will go in the opposite direction, and no matter how smart the later big model is, it will be of no use.
This market was previously dominated by several giants: OpenAI's text embedding series, Google's Gemini embedding model, and Amazon's Titan Embeddings. They are all proprietary models, charged based on the number of calls, and their prices are not cheap. For applications that require large-scale retrieval, this is a continuous cost burden.
Harrier's open source has changed this landscape. Three versions -27B, 2.7B, and 0.6B - are all open on Hugging Face under the MIT license. MIT is one of the most relaxed open source protocols with almost no usage restrictions. Developers can use, modify, and even commercialize it for free without paying Microsoft a penny.
This is not 'open source a censored version to make a fuss', this is' the best version of open source, for you to use'.
Strategic Value Interpretation: What Chess is Microsoft Playing?
Microsoft is not a charity organization, open source is the best embedding model, what is the picture?
The first layer of calculation: reduce the cost of relying on one's own ecology. Microsoft plans to deeply integrate Harrier into Bing search engine and AI proxy services. If the embedded model is proprietary, open-source, and free, then the cost of the entire technology stack will be reduced. Search and AI agents are services with extremely high call frequency, and the cost of embedding models accumulates. Mastering the core technology by oneself gives control over costs.
Second level abacus: Weakening competitors' sources of income. OpenAI's embedded model API is a considerable source of revenue. Why would developers have to pay for an open-source, better performing alternative? Isn't this stealing OpenAI's business? Don't forget, Microsoft is the major shareholder of OpenAI, but it is also an independent company with its own strategic interests. In the niche of embedding models, Microsoft has chosen competition rather than cooperation.
The third layer of abacus: occupying space in the era of AI agents. The material mentions that as artificial intelligence gradually moves towards the autonomy of multi-step tasks, the importance of embedded models will further increase. AI agents require frequent retrieval, understanding, and integration of information, with embedded models being the core component. Microsoft is now open sourcing the best embedding models, allowing developers to become accustomed to using Microsoft's technology stack, making it easier to choose Microsoft's solutions on AI proxy platforms in the future.
This is not a short-term tactical move, it is a long-term strategic layout.
Future trend: Open source is' equaling 'closed source
Harrier's open source marks an important leap in semantic representation capabilities for the open source ecosystem.
In the past few years, open source models have been catching up with closed source models, but the gap is significant. In the field of big language modeling, although the Llama series is narrowing the gap, GPT-4 still leads. But in the niche of embedding models, open-source Harrier has surpassed closed source OpenAI, Google, and Amazon.
This is not accidental. The training of embedded models is relatively controllable, unlike large language models that require astronomical amounts of computing power. It is reasonable for Microsoft to have data, computing power, and engineering capabilities to create the best models in this field.
More importantly, open source models have advantages that closed source models do not have: they can be deployed locally, customized and fine tuned, have no call costs, and do not leak data. For enterprise level applications, these advantages are more valuable than "5% performance lead".
In the future, we may see more cases of 'open source surpassing closed source'. It's not about surpassing every track, but about creating world-class products in certain key tracks and specific time points through open source communities and vendors.
Harrier is just a signal. The underlying logic of search, retrieval, and AI agents is being redefined. And this time, the power of definition lies in the hands of open-source developers.
