Anthropic says' 4.7 is not the strongest version ', but it solves AI's most annoying problem
Anthropic's pace has been really fast lately, with new moves almost every other day. But Claude Opus 4.7, released on April 17th, is a bit different.
Anthropic directly stated in the announcement, "This is not our most powerful model
The stronger Mythos Preview - according to them, it's still being polished and won't be available this time.
Putting this matter in another company may be seen as intentionally lowering one's profile and showing off one's appetite. But after reading the transcript, I think Anthropic's judgment this time is correct: although 4.7 is not the "strongest", it solves a more important problem than "smart" - reliability.

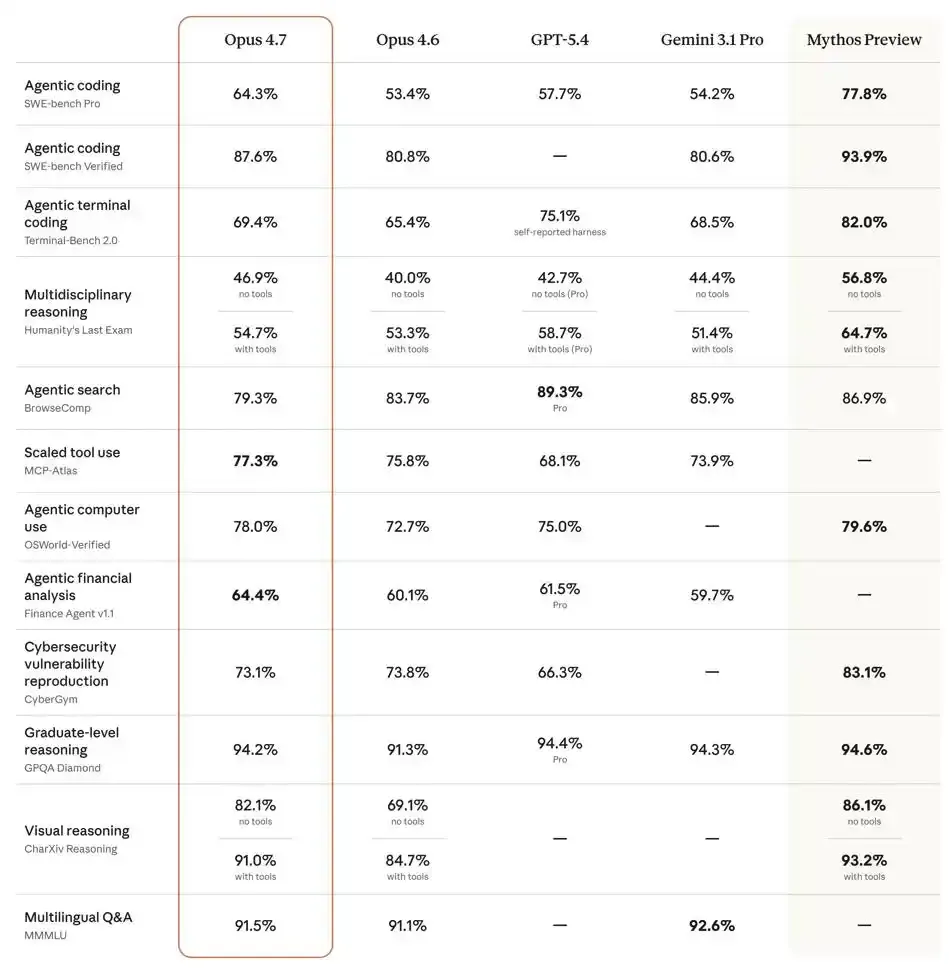
First, let's take a look at the score: programming ability has surged by 11 points
On the hardcore programming benchmark SWE bench Pro, Opus 4.7 jumped directly from 53.4% of the previous generation to 64.3%, with a single generation increase of nearly 11 percentage points.
What is the horizontal comparison level of this number? GPT-5.4 is 57.7%, while Gemini3.1 Pro is 54.2%. 4.7 exceeded both of these.
The visual inference benchmark CharXiv has jumped from 69.1% to 82.1%, with a key upgrade behind it: the addition of 2576 pixel long edge recognition capability and a more than 3-fold increase in image clarity compared to the previous generation.
The tool call evaluation of MCP Atlas ran 77.3%, while the legal AI platform Harvey's BigLaw benchmark scored 90.9%.
However, one indicator has reversed its trend: BrowseComp (Agentic Search Review) has slightly fallen from 83.7% to 79.3%, surpassed by GPT-5.4 and Gemini.
Anthropic's explanation for this is very interesting - it's not a decline in ability, but rather a personality trait of 4.7 "unwilling to randomly answer", who would rather report an error than make up for missing information. This answer is quite Anthropic.
What problem does it truly solve?
Beyond scores, what is more noteworthy is the changes in its behavioral patterns.
The feedback from the Replit manager after testing is: "It will refute me in technical discussions and help me make better decisions, really like a better colleague
The data science platform Hex has discovered a crucial improvement: 4.7 will directly report an error when encountering missing data, instead of inserting a "seemingly reasonable but completely incorrect" alternative value like the previous generation.
How big is the difference? For example:
When encountering uncertain data, the previous generation may fill in a number that is "calculated based on industry experience", which sounds quite professional but is actually an error that you are not aware of. 4.7 In the same situation, I will directly tell you, 'The data here is incomplete, and I cannot give you an accurate answer.'.
For people who need to use AI to make serious decisions, the act of 'if you don't know, say you don't know' is somewhat more important than 'giving an answer'.
The Notion team's testing also discovered a new behavior: 4.7 will first do mathematical proofs before starting to write system level code. This means that it will verify the feasibility of the solution before executing the task, rather than writing it up and then making changes.
What is the cost?
Of course, becoming stronger comes at a cost.
4.7 introduces a new tokenizer, which generates 1 to 1.35 times more tokens for the same text than before. Moreover, it tends to "think more for a while" in complex tasks, and the actual token consumption is almost bound to increase.
For this reason, Anthropic has added xhigh ultra-high level thinking intensity, and Claude Code has pulled all packages to this level by default. At the same time, a deep review command ultrareview, an Auto Mode extension for Max users, and a public beta version of the "Task Budget" function were launched to help developers control token spending.
Simply put, you spend more money, but it's more reliable. Whether it's worth it or not depends on your needs.
How strong is that 'stronger Mythos'?
On the same day as the release of 4.17, Anthropic also revealed information that Mythos Preview had just been opened to enterprises on a small scale under the name of "Project Glasswing" this month for network security research.
The reason is that the ability is too strong, the security assessment has not been completed, and it is not yet publicly released.
This is probably Anthropic style 'showing off' - it's not telling you 'how strong our new model is', but rather telling you' so strong that we ourselves feel it's risky to release it '.
