Liquid AI officially released LFM2.5-1.2B Thinking today, which is an inference model designed specifically for running entirely on the local side (On Device). This model achieves an astonishing breakthrough in lightweight design, requiring only 900 MB of memory to run smoothly on a regular smartphone. As a new generation model with the training goal of "concise reasoning", it can generate internal thinking trajectories before outputting the final answer, successfully transferring the complex reasoning ability that previously required data center level computing power to mobile terminals in the user's palm.
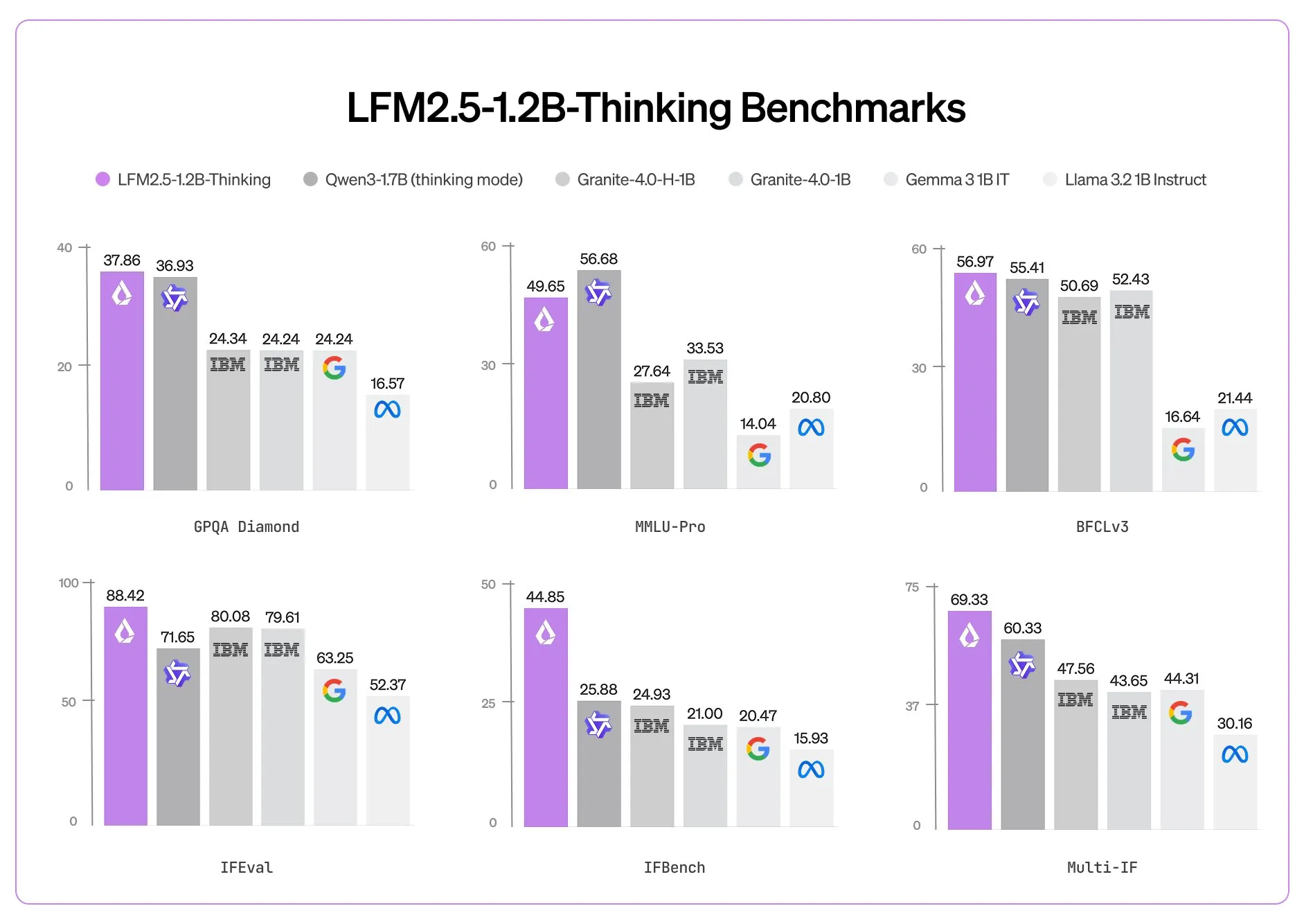
LFM2.5-1.2B Thinking is not only a compression of parameter quantity, but also an innovation in training methodology. Its core technical characteristics are mainly reflected in the following dimensions:
Concise reasoning: The model is trained to solve problems in the most direct and efficient way, reducing redundant calculations.
Internal Thinking Trajectory: Able to generate implicit thinking steps and output the final answer, significantly improving logical consistency.
Edge Scale Latency: Optimized for low latency scenarios, ensuring response speed on mobile devices meets real-time interaction requirements.
Multi domain specialization: Excellent performance in tool use, mathematical calculations, and complex instruction following.
Traditional end-to-end small models often sacrifice depth for speed and tend to generate answers directly. LFM2.5-1.2B Thinking introduces a slow thinking mechanism similar to System 2. By constructing an internal thought trajectory before outputting the results, the model can self correct logical fallacies, greatly improving the stability and interpretability of the answers.
Implementing this "chain/tree" thinking under the strict resource constraints of On Device is a huge engineering challenge. Liquid AI optimizes the inference path, allowing this complex thinking process to no longer rely on cloud computing power, but to be completed within the computing budget of local chips, truly achieving the goal of 'putting the brain in your pocket'.
What required a data center two years ago now only requires a mobile phone. The 900 MB memory footprint means that the vast majority of smartphones and even some high-end IoT devices on the market can easily support this model.
Zero privacy risk: Data does not need to be uploaded to the cloud and is processed entirely locally.
Offline availability: It can still work fully in weak or no network environments (such as airplanes, remote areas).
Ultimate optimization: Combining weight compression and linear attention techniques to maximize hardware utilization.
The release of LFM2.5-1.2B Thinking has opened up new application doors for end-to-end AI, especially in scenarios where privacy and real-time requirements are extremely high:
| Application field | specific scenario | core value |
| Education and Examinations | Local tutoring and exercise analysis | Protecting students' privacy and making it accessible in a non networked environment |
| Mobile Assistant | Complex instruction execution, mathematical calculations | Low latency response and strong tool calling capability |
| Industrial Inspection4 | Equipment troubleshooting and edge data analysis | Adapt to harsh network environments and make real-time decisions |
Attention: Despite impressive performance, when dealing with extremely long contexts or complex logical reasoning, due to limitations in model size and end side memory, it is still necessary to set reasonable expectations and do a good job of resource matching.
LFM2.5-1.2B Thinking successfully combines "local inference+concise thinking+tool capabilities" into one, marking a new stage of "thinking" in edge intelligence. It proves that high efficiency is no longer the patent of giant models, and small models can also unleash great wisdom through excellent algorithm design. It is recommended that developers and industry users closely monitor their subsequent release of benchmark data and open testing entrances.