On February 5, 2026, Anthropic officially announced the launch of ClaudeOpus 4.6 on the X platform. As the latest iteration of the flagship model, Opus 4.6 abandons the simple parameter stacking route and instead locks the core breakthrough in deep engineering implementation capabilities. It not only demonstrates unprecedented task planning and self correction capabilities, but also can stably handle agentictasks with longer spans and more complex logic. It is also the first to open a beta version of 1 million token long contexts at the Opus level. This milestone upgrade marks the official leap of AI long text processing capabilities from simple "reading comprehension" to the million level era of "controlling super large code repositories", providing a truly reliable infrastructure for enterprise level automated workflows and redefining the capabilities of intelligent code assistants.
From "Better Planning" to "More Capable of Running Long Tasks": Upgrading and Disassembling
The release of Opus 4.6 has not been too long since the previous version update, but it has taken a big step forward in the depth of product implementation. According to Anthropic's official press release, the core logic of this upgrade is to shift from "answering questions" to "solving complex workflows".
Key technological breakthrough: adaptive thinking and context compression
In order to support these complex intelligent agent behaviors, Anthropic has introduced several key technology updates at the API level, greatly enhancing developers' control over the model's "thinking process":
Adaptive Thinking: This is an extremely practical feature. Opus 4.6 no longer requires developers to manually specify "whether to think", it can dynamically decide whether to start deep inference based on the complexity of the problem. For simple queries, it will respond quickly to save costs; For complex logic, it will automatically perform in-depth deduction through Extended Thinking.
Effort Levels: In order to keep costs under control, the API now offers four levels of effort: Low, Medium, High (default), and Max. Developers can precisely control the computational resources invested in the model based on the value of the task.
Context Compaction (Beta): In response to the "forgetting" problem in long conversations, a new feature allows the model to automatically perform semantic level compression on early contexts when approaching window limits. This is a lifesaver for agents that require long-term memory and can effectively extend the lifespan of a single session.
128K Output Tokens: The output limit has been relaxed to 128000 tokens, which directly solves the pain point of being truncated when generating long reports or large code modules.
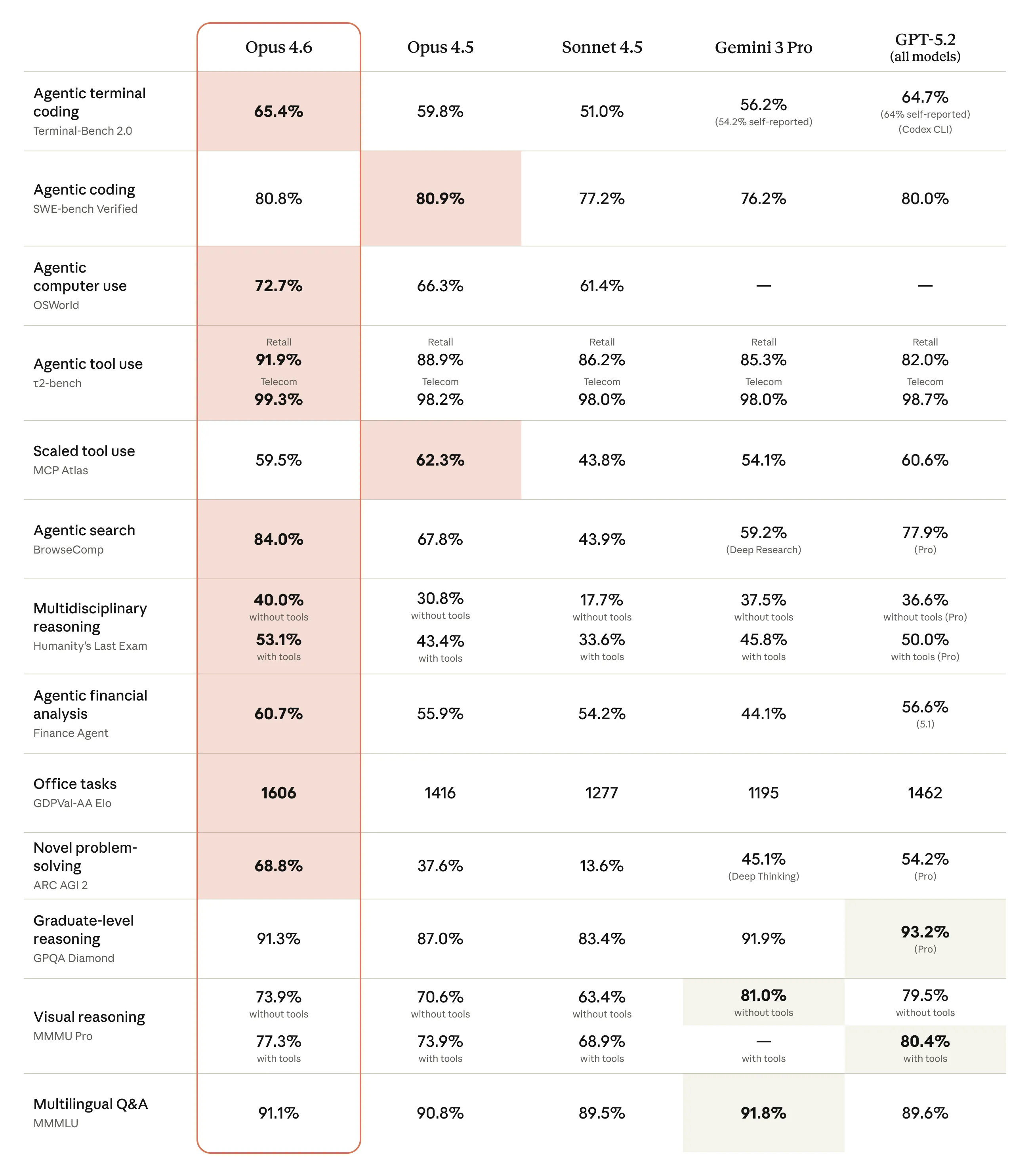
What about data: benchmark evaluation and price information
All technological upgrades ultimately return to data performance. The test data released by Anthropic this time is very hardcore, directly benchmarking against the current strongest competitor.
Engineering Capability and General Intelligence Evaluation
| In the Terminal Bench 2.0 test simulating a real programming environment, Claude Opus 4.6 scored 65.4% high. This benchmark test focuses on the actual operational ability of the agent in the terminal environment, directly reflecting the model's ability to solve complex programming tasks without human intervention. Terminal Bench 2.0 review data | On the GDPval AA (EloScore) ranking, which measures the ability to perform high-value knowledge work (finance, legal analysis), Opus 4.6 demonstrates dominance. It is about 144 Elo points higher than GPT-5.2. This means that in a direct confrontation, Opus 4.6 has a 70% chance of defeating the opponent. Comparison of Winning Rates for GDPval AA |
usability
Currently, ClaudeOps4.6 has been launched on mainstream cloud platforms such as claude.ai, official APIs, and Azure.
Applicable scenarios:Standard dialogue, short document analysis (≤ 200K context);Full analysis of ultra long books and code libraries (>200K context).