On January 6, 2026, the MiroMind team, co founded by Chen Tianqiao, founder of Shanda Group, and Dai Jifeng, former chief scientist of Megvii Technology, officially released its flagship search agent model MiroTrainer 1.5. This model achieved performance comparable to trillion level models with a parameter count of 30B, causing a sensation in the industry and opening up a new path for the development of large models.
In the fierce competition of parameter scale and million level context length across the industry, the MiroMind team has taken a different approach by using "Interactive Scaling" technology to outperform many mainstream trillion parameter models with only 1/30 parameter scale, and the inference cost has been reduced to 1/20 of competitors. This breakthrough confirms the core proposition of AI development: the essence of intelligence lies not in remembering the whole world, but in knowing how to 'discover'.
Performance Exceeding: Small Volume Boosts Large Capacity
The MiroTinker 1.5 series has launched two versions: the lightweight version with 30B parameters and the flagship version with 235B parameters. In multiple authoritative benchmark tests, this series of models has demonstrated remarkable performance.
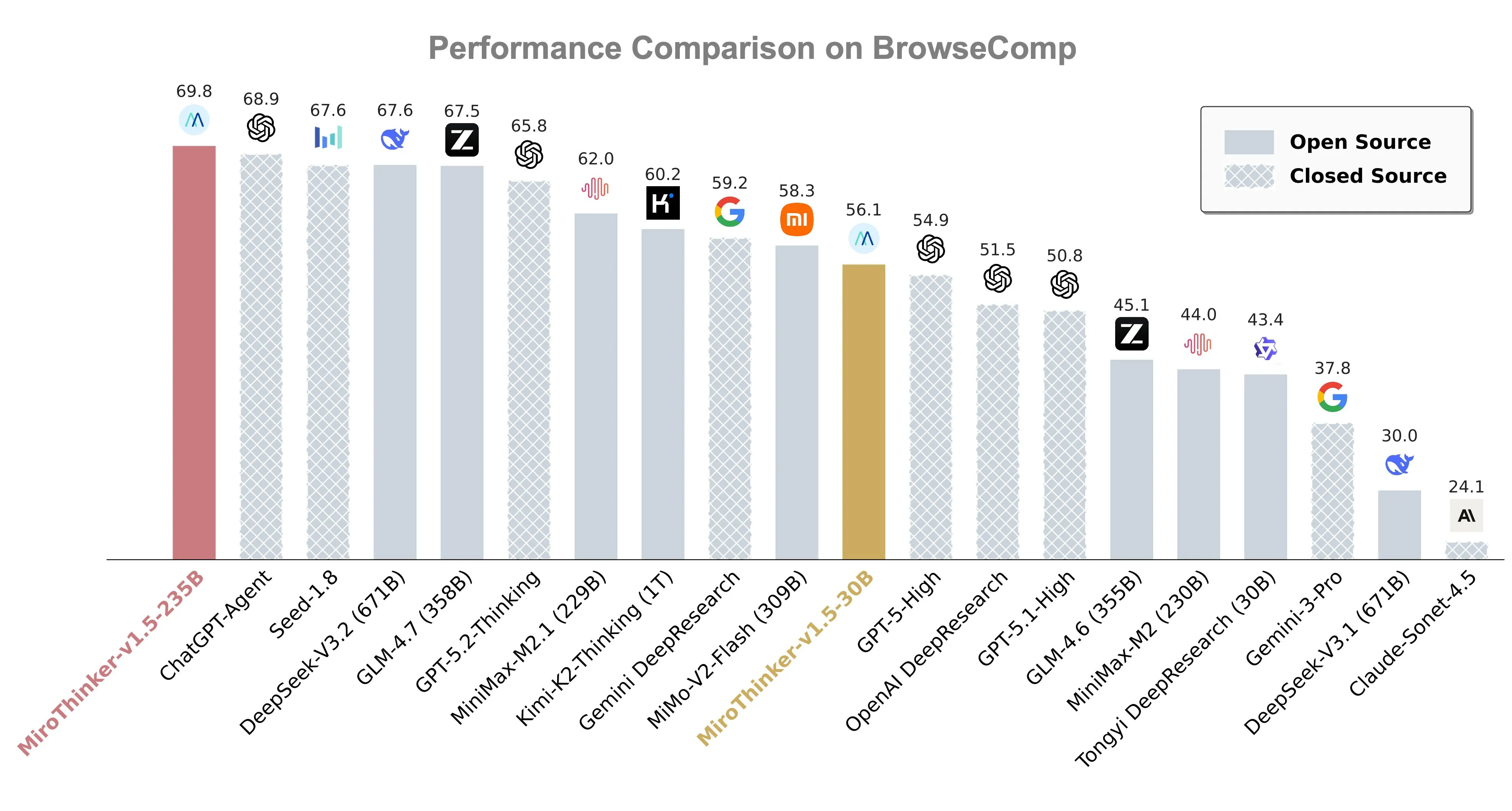
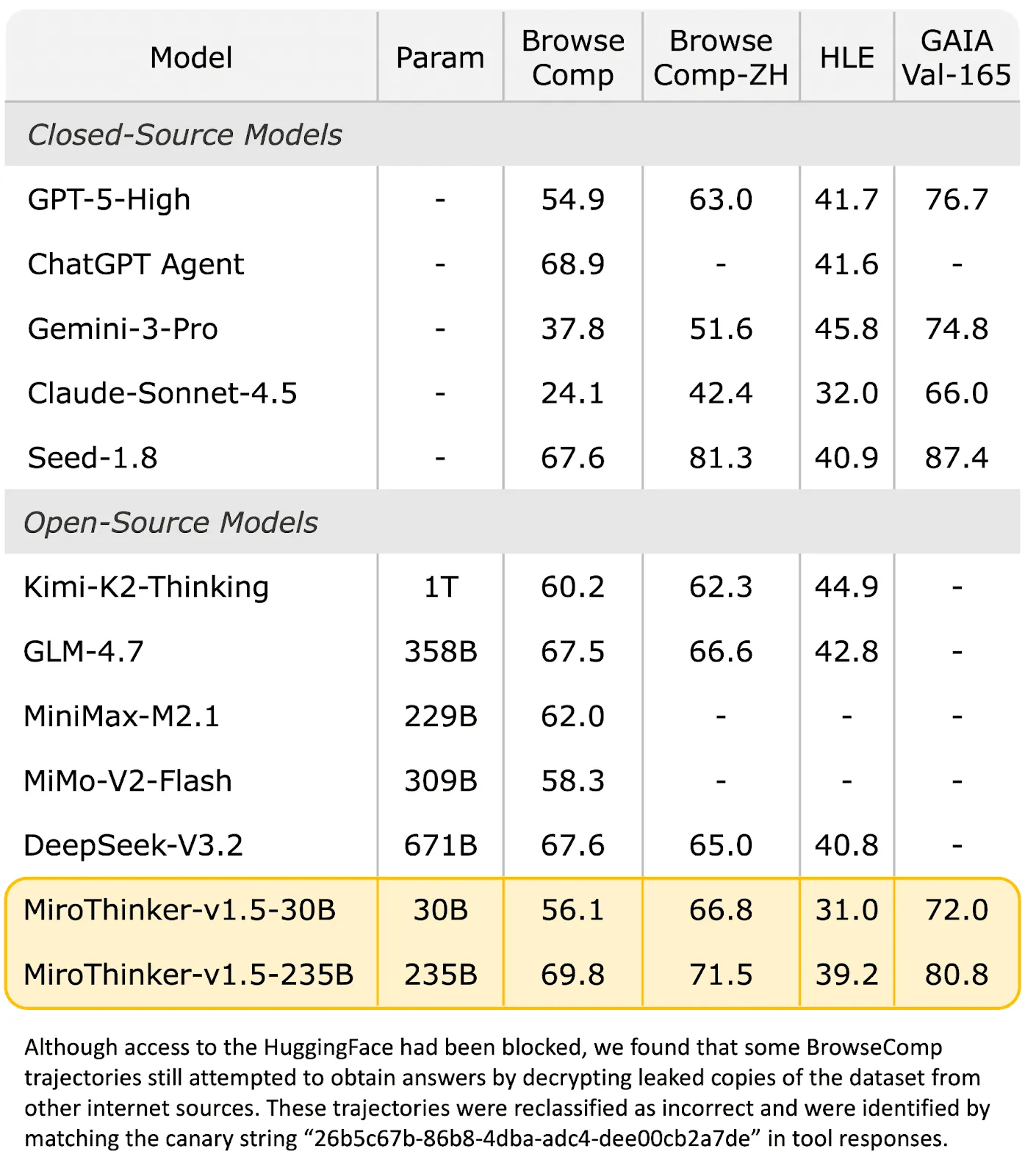
In the BrowseComp standard test, MiroTinker-v1.5-235B scored 69.8%, surpassing ChatGPT Agent's 68.9%; The 30B version, with a score of 56.1%, still performs well even though the number of parameters is much lower than models such as GPT-5.1-High (358B) and GLM-4.7 (358B).
What is even more remarkable is the benchmarking performance against Kimi-K2 Thinking. Faced with a competitor with a parameter scale of trillions, MiroThinker-v1.5-30B not only achieved a 4.5% performance lead in BrowseComp ZH testing, but also achieved an overwhelming advantage in inference cost - the cost of a single call is only $0.07, which is 1/20 of the opponent's, and the inference speed is faster. This comparison fully proves that 'bigger' does not necessarily mean 'stronger'.
In other benchmark tests for search agents, the MiroThinker series has also consistently topped the charts, repeatedly entering the top tier globally. The team's sustained leading performance in Polymarket screening problem prediction and FutureX global rankings has further validated the application value of the model in real-world scenarios.
Technical Core: From "Candidate Mode" to "Scientist Mode"
The traditional large-scale model follows the Scaling Law, which essentially stores human knowledge through massive parameters. This "examinee model" attempts to memorize all Internet content into the model. When encountering unknown problems in fields such as biology, models often fabricate seemingly reasonable answers based on probability distributions - this is the root cause of AI hallucinations.
The solution proposed by the MiroThinker team is a paradigm shift: shifting from "internal parameter extension" to interactive scaling centered around "external interaction". This concept was first systematically proposed in MiroThinker 1.0, emphasizing that as the frequency and depth of tool interaction increase, the research-based reasoning ability will steadily enhance, forming a third scalable dimension after model size and context length.
MiroTrainer 1.5 further deepens this mechanism and internalizes it as a core competency that runs through the entire training and reasoning process. The model is trained to play the role of a 'scientist', whose core ability is not rote memorization, but diligent verification. When encountering difficulties, instead of giving the highest probability guess, perform a "slow thinking" research cycle: propose hypotheses → query the external world to obtain data and evidence → discover mismatches → correct hypotheses → re validate until the evidence converges.
The development team deliberately controlled the model parameters at a lightweight scale of 30B-200B, not to save computing power, but to invest computing power in the most important aspect - external information acquisition and interaction. The team's pursuit is not to equip the model with the 'heaviest brain', but to cultivate its' most diligent hands'. When the model has both a research-oriented confirmation mechanism and temporal causal constraints, the interactive process around external information acquisition truly achieves "discovery intelligence", which is also the underlying logic for small parameter models to achieve the capability of large models.
Training Innovation: Two Key Technical Supports
Interactive extension during the training phase
The traditional chain of thought (CoT) modeling is essentially a linear extrapolation of the knowledge space within the model, and inference bias accumulates as the path lengthens, ultimately leading to logical collapse. MiroTrainer 1.5 fundamentally solves the dilemma of isolated reasoning by moving interactive extensions from additional capabilities in the inference phase to the core mechanism in the training phase.
During the training process, the team deliberately weakened the reward for "perfect one-time reasoning" and instead reinforced the following behavioral patterns:
Evidence exploration (active verification): Encourage the model to break down each key judgment into verifiable sub hypotheses, and actively initiate external queries, searches, and comparisons. The training objective is no longer the conclusion itself, but the process of finding reliable evidence. High confidence outputs lacking source support are systematically penalized during training.
Iterative verification (multiple rounds of validation and self correction): Reasoning is not considered a one-time path, but a process that can be repeatedly traced and corrected. The model needs to continuously test existing judgments through cross validation in interactions. Once evidence conflicts are found, hypotheses must be explicitly adjusted instead of "continuing reasoning with errors".
Anti illusion (systematic filtering shortcut): Zero tolerance for reasoning shortcuts that appear reasonable but lack practical basis. Training evaluation is not only about whether the answer is correct, but more importantly, how the answer is obtained; Any path that relies on statistical associations, pattern memory, or implicit priors to bypass evidence verification is marked as low-quality reasoning.
Through this training method, MiroTrainer 1.5 gradually forms an "instinctive response": facing uncertainty, interact first and then judge; In the face of high-risk conclusions, verify first and then converge. This makes the model no longer need to fully internalize massive world knowledge as parameters, but learn to quickly and accurately 'borrow' from the external world when needed.
Time sensitive training sandbox
The time sensitive training sandbox is the key to solving the problem of causality. Standard large model training often takes a "God's perspective" - the model sees the final answer in static training data, leading to Hindsight Bias, where the model only recalls the past rather than predicting the future.
MiroTinker's time sensitive training sandbox forces the model to learn inference under strict temporal visibility constraints: it can only interact with information published before a specific timestamp of the problem.
Controllable data synthesis engine: Build a data synthesis system that covers multiple types of tasks, with controllable difficulty and timestamps. The 'correct answer' to each question is not a static label, but dynamically evolves over time stamps; The model must make judgments based on the available information at the time under strict information visibility constraints, and the validation process also explicitly introduces timestamp constraints to ensure that inference and scoring conform to real-world temporal logic.
Time sensitive training mechanism: adopting strict timestamp and information visibility constraints to completely eliminate future leaks; Each step in model training can only interact with information published before the current timestamp.
Under this training paradigm, the model is forced to learn reasoning and correction under real conditions of incomplete information, noise, and signal delay, rather than relying on "standard answers" in static datasets. Time transforms from a background variable to a core constraint that shapes the behavior and reasoning of the model, making it closer to the cognitive and decision-making processes of the real world.
Application scenarios: from financial markets to cultural and entertainment
MiroTinker 1.5 demonstrates powerful capabilities in multiple practical application scenarios. In financial market analysis, models can deeply analyze major events that affect the NASDAQ index of the US stock market and their possible impacts; In the field of entertainment and culture, it is possible to predict the popularity of Oscar Best Picture nominations in 2026; In terms of sports competition, the possibility of teams advancing to the 2026 Super Bowl can be analyzed.
At present, users can experience the in-depth research function of the model for free through the MiroMind official website. The model weights have been open sourced on Hugging Face and Github platforms for developers and researchers to explore and use.
Technical concept: Better researchers, not bigger brainsThe MiroMind team was co founded by renowned entrepreneur Chen Tianqiao and AI scientist Dai Jifeng, dedicated to building "Native Intelligence" - AI systems that reason through interaction rather than memory. The team firmly believes that this is the right path to a more powerful, reliable, and efficient AI system.
This concept is particularly valuable at the beginning of the 2026 big model arms race. When the industry is generally addicted to the "violent aesthetics" of parameter stuffing, the MiroTinker team has proven through practical actions that the future of AI lies not in building larger brains, but in cultivating better researchers. The singularity of intelligence is not "recording the world into parameters", but "discovery based intelligence" - true intelligence does not rely on omniscience, but on the ability to research, verify, and correct errors.
Just as top intelligence officials can quickly gather evidence externally while rigorously discerning authenticity internally; Like rigorous researchers approaching the truth in uncertainty, ultimately transforming 'predicting the future' from privilege to ability. This may be the more efficient and sustainable technological path towards AGI.

